
Machine Learning Applications in Genomics Life Sciences by Ernest Bonat, Ph.D.
Updated: Jan/13/2025
Machine Learning (ML) has found various applications in the field of Life Sciences, revolutionizing research and development in numerous ways. Some of the main applications of Machine Learning in Life Sciences include:
- Drug Discovery and Development
- Genomics and Personalized Medicine
- Disease Diagnosis and Prognosis
- Biomedical Image Analysis
- Bioinformatics and Computational Biology
- Biopharmaceutical Manufacturing
- Clinical Trials and Research Design
- Epidemiology and Public Health
The ten most important applications of Machine Learning in genomics can be found in the following paper: “10 Applications of Machine Learning in Genomics”. They are Genome Sequencing, Predictive Testing, Pharmacogenomics, Data Clustering, Genetic Disorders, Genetic Research Studies, Gene Modification, Gene Ontology, Principal Component Analysis, and Genetic Algorithm Study.
Machine Leaning Applications in Genomics Life Sciences Summary
- “Advanced Synthetic DNA Sequence Generation and Preprocessing for Natural Language Processing”. Ernest Bonat, Ph.D., Jan 13, 2025.
- “Using Machine Learning Models for Breast Cancer Diagnosis — A complete Machine Learning Project Workflow for Life Sciences”. Ernest Bonat, Ph.D., Chad Turner, Nov 9, 2024.
- “Advanced Paternity DNA Sequence Classification Using Dynamic Programming and Machine Learning Algorithms. Part 1”. Ernest Bonat, Ph.D., Mohamed Abdulaziz Eisa, B.Sc. AI, Sep 12, 2024.
- “Q & A ChatBot — A Generative AI Application Using Large Language Models”. Pankaja Ambalgi, M.S., Ernest Bonat, Ph.D., Jul/31/2024.
- “Apply Machine Learning Algorithms for Classification Drug Discovery Data”. Ernest Bonat, Ph.D., Apr 27, 2024.
- “DNA Sequences Preprocessing Using PySpark Library”. Ernest Bonat, Ph.D., Feb 24, 2024.
- “ETL Package Development with 3-Tier Architecture for Data Engineering”. Ernest Bonat, Ph.D., Jan 23, 2024.
- “Advanced DNA Sequence Text Classification Using Natural Language Processing”. Ernest Bonat, Ph.D., Dec 22, 2023.
- “Fast DNA Sequence Data Loading — List vs. NumPy Array”. Ernest Bonat, Ph.D., Aug 9, 2023.
- “DNA Sequence String Conversion to Label Encoder for Machine Learning Algorithms”. Ernest Bonat, Ph.D., April 18, 2023.
- “Advanced DNA Sequences Preprocessing for Deep Learning Networks”. Ernest Bonat, Ph.D., Mar 29, 2023.
- “Building Machine Learning Clustering Models for Gene Expression RNA-Seq Data”. Ernest Bonat, Ph.D., Dec 28, 2022.
- “RNA-Seq Gene Expression Classification Using Machine Learning Algorithms”. Ernest Bonat, Ph.D., Aug 6, 2022.
- “Web Deployment of Genomics Machine Learning Models Using Flask Web Framework”. Ernest Bonat, Ph.D., June 18, 2022.
- “Apply Machine Learning Algorithms for Genomics Data Classification”. Ernest Bonat, Ph.D., Bishes Rayamajhi, MS. February 03, 2021.
- “Melanoma Skin Binary Image Classification using XGBoost Algorithm”. Tyler Yarnell, Ernest Bonat, Ph.D. April 10, 2019.
- “Using C# to call Python RESTful API Web Services with Machine Learning Models”. Ernest Bonat, Ph.D. Jan 24, 2018.
- “Using C# to run Python Scripts with Machine Learning Models”. Ernest Bonat, Ph.D. July 24, 2018.
- “Refactoring Python Code for Machine Learning Projects. Python “Spaghetti Code” Everywhere!”. Ernest Bonat, Ph.D., Jun 18, 2018.
…
1. “Advanced Synthetic DNA Sequence Generation and Preprocessing for Natural Language Processing”. Ernest Bonat, Ph.D., Jan 13, 2025.

Abstract: This paper presents a robust approach to generating and preprocessing synthetic DNA sequences for application in Natural Language Processing (NLP) algorithms and data-driven Machine Learning (ML) pipelines. Using a small promoter gene sequence dataset as a foundation, the study addresses the challenge of limited data availability by employing synthetic data generation through the Gretel platform and developing an ETL (Extract, Transform, Load) pipeline for preprocessing. The proposed methodology facilitates the creation of high-quality datasets for accurate ML model training, validation, and production deployment, with significant implications for Bioinformatics and Life Sciences.
2. “Using Machine Learning Models for Breast Cancer Diagnosis — A complete Machine Learning Project Workflow for Life Sciences”. Ernest Bonat, Ph.D., Chad Turner, Nov 9, 2024.

Abstract: This project utilizes the “Breast Cancer Wisconsin (Diagnostic) Dataset” from the University of California Irvine Machine Learning Repository, available on Kaggle, to build a predictive Machine Learning (ML) model for breast cancer diagnosis. The dataset contains digitized imaging data obtained from fine needle aspiration (FNA) procedures of breast masses. Each sample image includes 30 features derived from cell nuclei, analyzed through a contour model known as a “snake,” with measurements such as mean, worst value, and standard error. The dataset comprises 569 samples, with 357 benign and 212 malignant diagnoses. The primary goal is to construct an accurate ML classification model in Python to predict breast cancer diagnoses based on these features. The research focuses on identifying cell nucleus characteristics most correlated with malignant diagnoses, employing supervised ML algorithms to achieve optimal prediction accuracy.
3. “Advanced Paternity DNA Sequence Classification Using Dynamic Programming and Machine Learning Algorithms. Part 1”. Ernest Bonat, Ph.D., Mohamed Abdulaziz Eisa, B.Sc. AI, Sep 12, 2024.
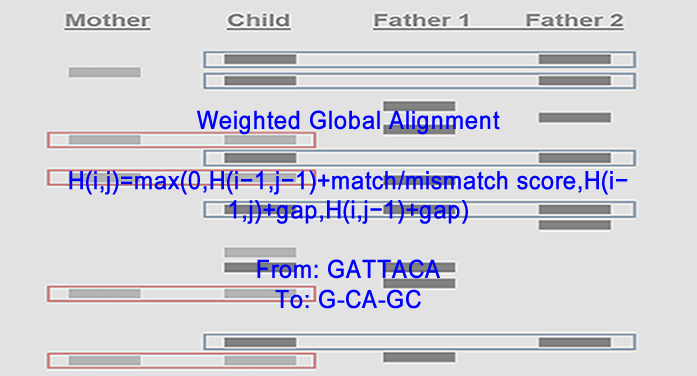
Abstract: This research explores the use of Dynamic Programming and Machine Learning algorithms to enhance paternity DNA sequence classification, focusing on the efficiency and accuracy of sequence alignment in paternity testing. Paternity tests, essential for establishing biological relationships, traditionally use DNA sampling methods for high-precision results. To improve the computational performance of sequence alignment, this study aims to fully parallelize key algorithms, particularly Smith-Waterman (SW) for local alignment and Needleman-Wunsch (NW) for global alignment, utilizing cost-effective hardware and software solutions. While effective for DNA sequences, the approach has limitations, such as dependency on equal-length sequences and variability in adaptability to alternative alignment methods. The proposed model seeks to reduce computational and power demands, making it a viable alternative for laboratory and clinical applications.
4. “Q & A ChatBot — A Generative AI Application Using Large Language Models”. Pankaja Ambalgi, M.S., Ernest Bonat, Ph.D., Jul/31/2024.

Abstract: Imagine a Q&A application capable of answering your questions in a specific domain or from a knowledge base made up of a company’s data in the form of documents, websites, databases, and more. These documents could include business records, patient and doctor/patient conversations, or proprietary data of a company. To achieve such a fine-tuned Q&A application, we use the Retrieval-Augmented Generation (RAG) technique. Using RAG, we can extend the capabilities of Large Language Model (LLM) to refer to the knowledge base for context and required data without the need for retraining them. Fine-tuning LLM with the help of the RAG process is the core concept on which this application is built. In this paper we’ll show how to fine tune the LLMs with the set of personal documents using RAG technique.
5. “Apply Machine Learning Algorithms for Classification Drug Discovery Data”. Ernest Bonat, Ph.D., Apr 27, 2024.

Abstract: Drug Discovery is the process by which new medications are identified and developed. It involves a series of steps aimed at finding compounds that have the potential to treat or prevent diseases. Machine Learning can play a significant role in various stages of the Drug Discovery process, enhancing efficiency, accuracy, and speed. In this paper, the PadelPy library proves to be a good solution to calculate molecule fingerprint descriptors for Machine Learning algorithms. The Random Forest classifier model provides a high accuracy score for predicting active and inactive compounds in the Drug Discovery process. It was demonstrated that Machine Learning tree and boosting algorithms perform better for classifying Drug Discovery compound datasets.
6. “DNA Sequences Preprocessing Using PySpark Library”. Ernest Bonat, Ph.D., Feb 24, 2024.

Abstract: PySpark is the Python API for Apache Spark, a powerful open-source distributed computing system designed for big data processing and analytics. Spark provides an easy-to-use interface for parallel processing large datasets across a cluster of computers. In PySpark, Transformers are functions that take a DataFrame as input and output another DataFrame with modified features. Based on the DNA sequence preprocessing ETL algorithm presented in ‘Advanced DNA Sequences Preprocessing for Deep Learning Networks,’ this paper will demonstrate how to implement the same logic using the PySpark library. The splice-junction gene sequences dataset will be utilized in this paper for DNA sequence preprocessing. A new ‘shape’ attribute for the PySpark DataFrame was designed and developed. A generic load function was created to return the initial DataFrame and the used Spark session. The same PySpark data transform pipeline logic and code can be applied to any required ETL process for any life science dataset preprocessing.
7. “ELT Package Development with 3-Tier Architecture for Data Engineering”. Ernest Bonat, Ph.D., Jan 23, 2024.

Abstract: One of the main tasks of Machine Learning (ML) is data preprocessing (cleansing). In general, this task constitutes about 60% — 70% of the entire ML project. There is a significant amount of data preprocessing work to be done before applying your initially selected ML method. The company’s Engineering Department is in charge of providing and maintaining these tasks, handled by specialized Data Engineers and ETL Developers. In this paper, a new ETL package design was proposed using traditional 3-tier architecture business application development. The complete Python pipeline process code is provided. An ETL static library was developed to reduce the amount of application code and eliminate code duplication.
8. “Advanced DNA Sequence Text Classification Using Natural Language Processing”. Ernest Bonat, Ph.D., Dec 22, 2023.

Abstract: A DNA sequence is a simple text or a string data type in a programming language. Considering it as text, it could be possible to apply Natural Language Processing (NLP) to determine if this Artificial Intelligence (AI) algorithm can be utilized for DNA sequence classification. NLP is an AI field that focuses on enabling computers to understand, interpret, generate, and respond to human language in a valuable and meaningful manner. It involves the interaction between computers and humans through natural language. In this paper, three primary DNA sequence k-mer preprocessing methods were developed and tested, including generation, concatenation, and vectorization steps.
9. “Fast DNA Sequence Data Loading — List vs. NumPy Array”. Ernest Bonat, Ph.D., Aug 9, 2023.

Abstract: The genomic DNA sequence data can be imported from various sources, such as files, databases, clouds, and more. To use this data for statistical analysis, it must be loaded into a programming data object based on the chosen language. This paper compares the loading of DNA sequence data between List and NumPy arrays. NumPy is a fundamental package for scientific computing in Python, specifically developed for numerical data. The paper recommends that well-implemented functions include docstring comments and exception handling trace backs as good programming practices. The execution runtime test was conducted with different sizes of DNA sequence datasets. It is suggested that, when loading DNA sequence string datasets, the Python List object should be preferred. It has been demonstrated to be faster than NumPy arrays.
10. “DNA Sequence String Conversion to Label Encoder for Machine Learning Algorithms”, Ernest Bonat, Ph.D., April 18, 2023.

Abstract: Machine learning algorithms require datasets to be in numerical values. By definition, DNA sequence datasets are of the string (text) data type. It is very important for any bioinformaticians and computational biologists to know how to convert DNA sequence string datasets to numerical values. This paper proposes to use label encoding as a data preprocessing step to fulfill this requirement. A label encoder class object was developed to convert DNA sequence string CSV files to DNA label encoded CSV files and viceversa. This class object can be used to generate synthetic DNA sequence datasets. The source code can be downloaded from a GitHub repository.
11. “Advanced DNA Sequences Preprocessing for Deep Learning Networks”. Ernest Bonat, Ph.D., Mar 29, 2023.

Abstract: I have received many questions about processing DNA sequence strings for Deep Learning Network applications. This paper covers the following topics: DNA sequence string one-hot encoding, padding, dataset cleaning, and validation. A new ETL data pipeline process has been developed to generate synthetic DNA sequence data to solve label imbalanced classes. Because of this, manual DNA sequence generation is no longer required. The Convolutional Neural Networks (CNN) algorithm was applied to both imbalanced and balanced DNA sequence class datasets. The results of the CNN demonstrate better model performance with balanced classes, as expected. I am working on applying Generative Adversarial Networks (GAN) to generate synthetic DNA sequence datasets. This is a very challenging topic for Bioinformatics and Computational Biology scientists to understand and apply today.
12. “Building Machine Learning Clustering Models for Gene Expression RNA-Seq Data”. Ernest Bonat, Ph.D., Dec 28, 2022.
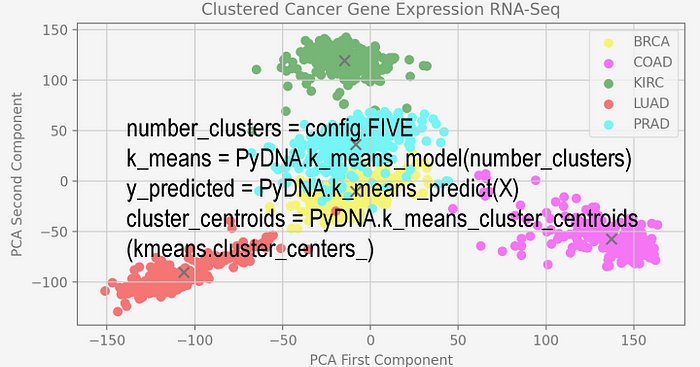
Abstract: This paper covers the following Machine Learning techniques: K-Means clustering, handling imbalanced classes using SMOTE, PyDNA library for DNA sequence analysis, PCA for feature dimensionality reduction, the Elbow Method and the Kneed library for selecting the optimal number of clusters, the Adjusted Rand Index metric for evaluating clustering performance, and clustering Silhouette Analysis. Some potential clustering applications in Bioinformatics include identifying groups of patients who respond differently to medical treatments for specific diseases and revealing groups of functionally related genes with similar expression patterns based on their proximity. Visualizing, interpreting, and analyzing high-dimensional and large-scale biological data can be challenging unless the data is organized into clusters. Another example is clustering genes or biomedical images to uncover hidden patterns from unlabeled datasets.
13. “RNA-Seq Gene Expression Classification Using Machine Learning Algorithms”. Ernest Bonat, Ph.D., Aug 6, 2022.

Abstract: This paper discusses the application of classification Machine Learning algorithms to an RNA-Seq gene expression dataset. Typically, such datasets are multi-dimensional with thousands of unlabeled columns. To expedite the process of Machine Learning model development and optimization, a data loading logic is proposed using pandas objects for serialization and deserialization. The SMOTE algorithm is implemented to handle imbalanced target classes before applying classification algorithms. The PCA algorithm is used for feature reduction of the Pan-Cancer Atlas dataset. The results show that traditional classification gradient boosting models, including the Light Gradient Boosting Machine algorithm, offer better model performance. It is recommended to apply both traditional and modern Machine Learning classification algorithms to genomic datasets to determine which model provides the most accurate prediction results.
14. “Web Deployment of Genomics Machine Learning Models Using Flask Web Framework”. Ernest Bonat, Ph.D., June 18, 2022.

Abstract: The final phase of a Machine Learning project workflow is deploying the final model into a production environment to make practical business decisions based on selected data. The Flask web microframework provides a simple way to design and develop genomics RESTful Web APIs and UI for end-users. The developed genomics Web APIs enables binary classification of single and multiple DNA sequence strings. In this paper, an LSTM classification model was deployed and tested on the web. A DNA sequence binary classification web application was implemented for end-users.
15. “Apply Machine Learning Algorithms for Genomics Data Classification”. Ernest Bonat, Ph.D., Bishes Rayamajhi, MS. February 03, 2021.

Abstract: This paper presents the structure of DNA/RNA/protein sequences and their manipulation using Python Data Ecosystem libraries. It will demonstrate how ML algorithms can be used for classification and prediction of DNA/RNA/protein sequences. A comparison table of traditional and modern ML classification algorithms for genomic datasets will be provided. Additionally, a simple Python library, PyDNA, will be presented for DNA/RNA/protein sequence string processing and ML classification algorithms. It is recommended to use NumPy ndarrays wherever possible to increase the performance of large DNA sequence string processing. The main DNA sequence string encodings will be presented and analyzed, including Label Encoding, One-hot Encoding, and K-mer Counting. It is strongly recommended to apply all traditional and modern ML classification algorithms to any genomic dataset and find out which model provides the best prediction results.
16. “Melanoma Skin Binary Image Classification using XGBoost Algorithm”. Tyler Yarnell, Ernest Bonat, Ph.D. April 10, 2019.

Abstract: Melanoma is a form of skin cancer that usually is visible, so detection using image classification can be applied to quickly and easily predict the type of spot that visibly appears on the surface of the skin. Further, the tooling required of medical professionals utilizing Machine Learning algorithms can be constructed to run on relatively cheap platforms compared to traditional modes of detection (e.g. biopsy) which are costly, less timely, and require higher overhead. XGBoost is a common Machine Learning algorithm today. It is ubiquitous in Kaggle competitions both for its effectiveness and ease of use. In fact, it’s so successful that it is often used off-the-shelf by many Data Scientists just to explore the feature space, do some initial evaluation benchmarking, and assist with feature engineering work.
17. “Using C# to call Python RESTful API Web Services with Machine Learning Models”. Ernest Bonat, Ph.D. Jan 24, 2018.
Abstract: The main idea of this paper is to explore how business applications developed in C# can call Python Machine Learning trained models. This can be achieved by building Python RESTful API web services with ML trained models, which would allow any C# .NET business application to consume them for production Data Analytics projects. Standard HTTP client namespaces can be used to accomplish this. To avoid content hardcoding, a JSON data class encapsulation was designed and developed. To reduce development time and code, a simple OOP methodology was implemented using super/sub classes for any ML projects. For production Python ML projects development and deployment, class interfaces and API unit tests are required. A simple configuration application file can be used to avoid hardcoding Python ML settings, parameters, and model hyperparameters.
18. “Using C# to run Python Scripts with Machine Learning Models”. Ernest Bonat, Ph.D. July 24, 2018.

Abstract: The possibility of running Python script files with any developed Machine Learning models in Microsoft C# could be a good solution for companies that want to maintain their main development infrastructure. The paper will demonstrate how C# code can allow input/output of any necessary model parameters. This solution will enable any Microsoft C# business application to integrate Machine Learning models developed in Python using any of the Python Data Ecosystem frameworks, making it an excellent idea for a robust .NET system architecture. This could be applied using Java, C++, and other programming languages. The complete code to run a Python script file with an image classification model in C# is provided.
19. “Refactoring Python Code for Machine Learning Projects. Python “Spaghetti Code” Everywhere!”. Ernest Bonat, Ph.D., Jun 18, 2018.

Abstract: ”Python ‘Spaghetti Code’ Everywhere!” is a phrase that describes a situation where Python code has become overly complex, convoluted, and difficult to understand or maintain. “Spaghetti code” is a term used to describe code that is tangled and twisted, much like a plate of spaghetti, making it hard to follow the flow of execution. In Python, which is known for its readability and simplicity, encountering spaghetti code is particularly frustrating because the language is designed to promote clear and concise coding practices. When Python code becomes spaghetti-like, it can result from poor design, lack of adherence to coding standards, excessive nesting, and a lack of modularization or abstraction.
